CIP: Draft
title: Aligning quoting and solving behavior of solvers
author: Haris Angelidakis, Felix Henneke
status: Draft
created: 2025-07-02
Simple Summary
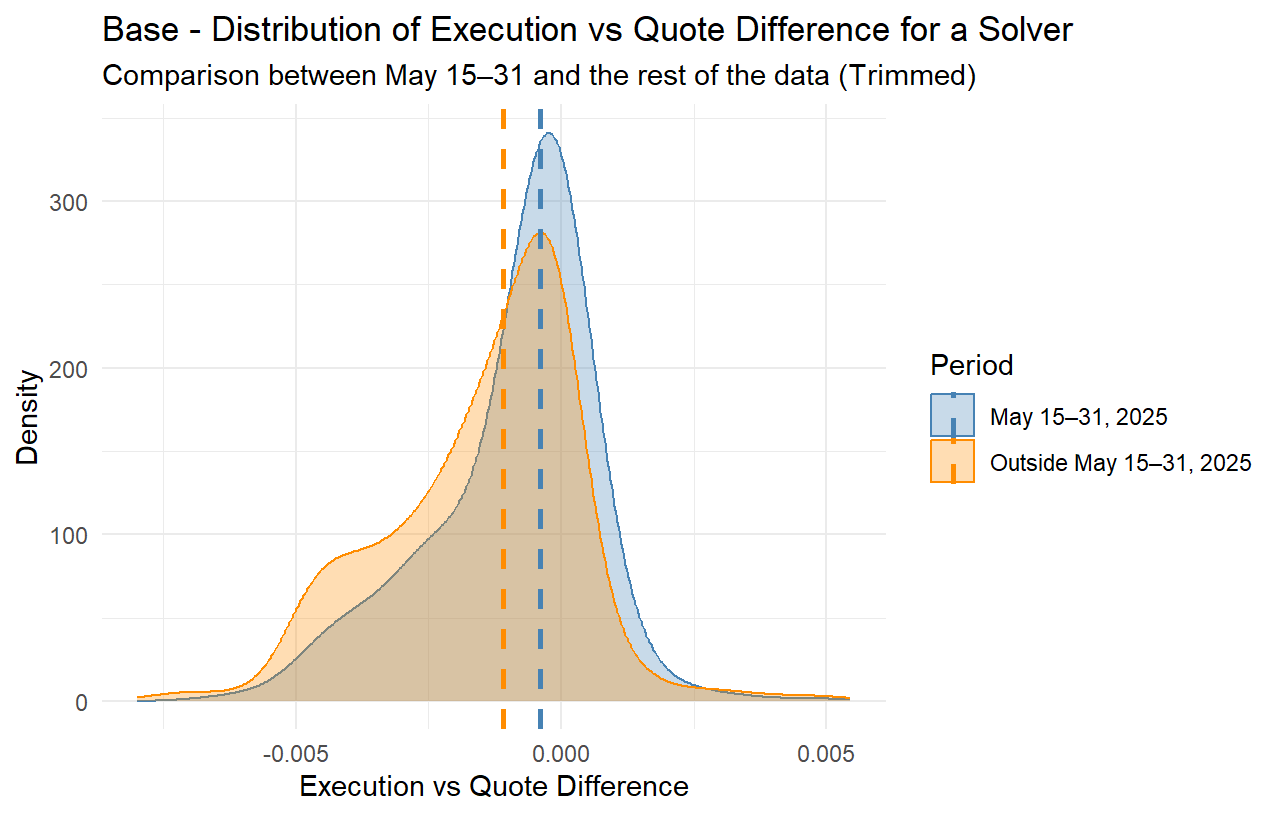
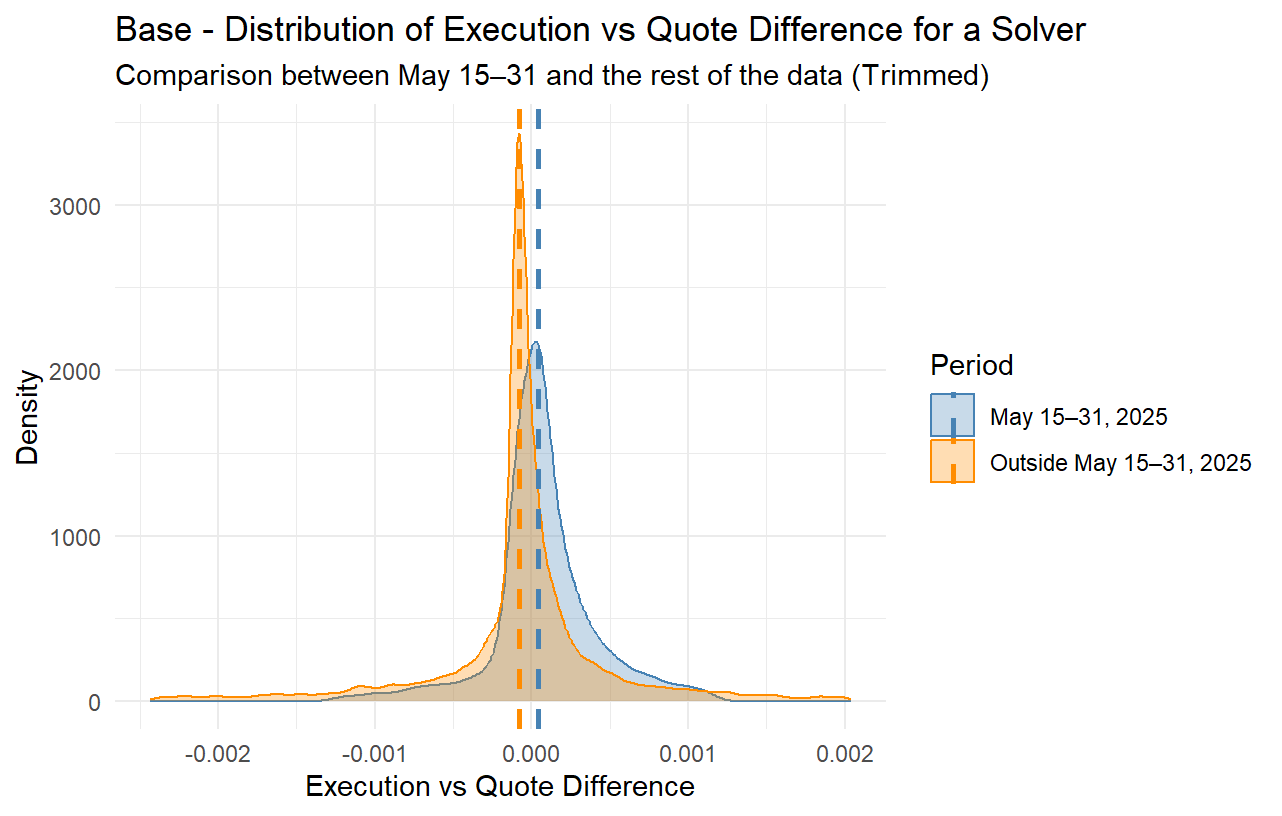
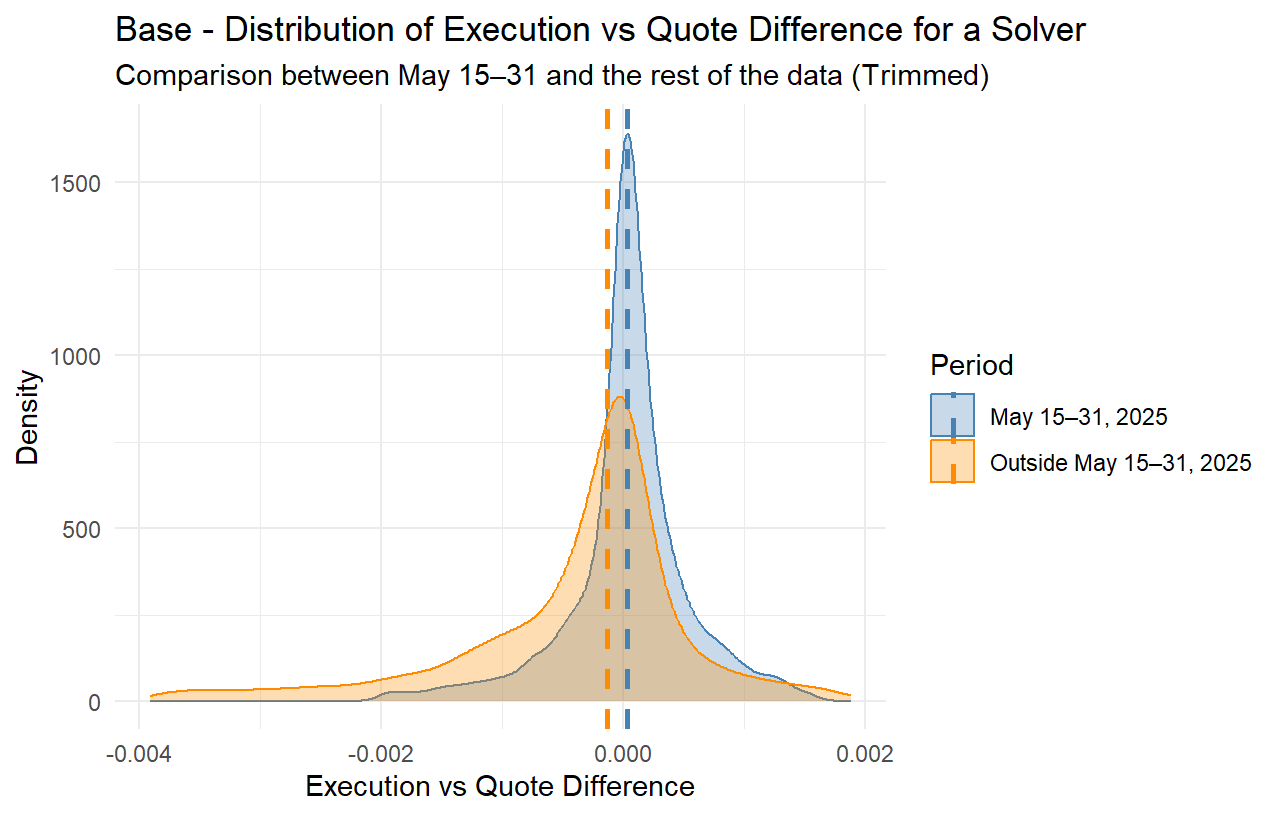
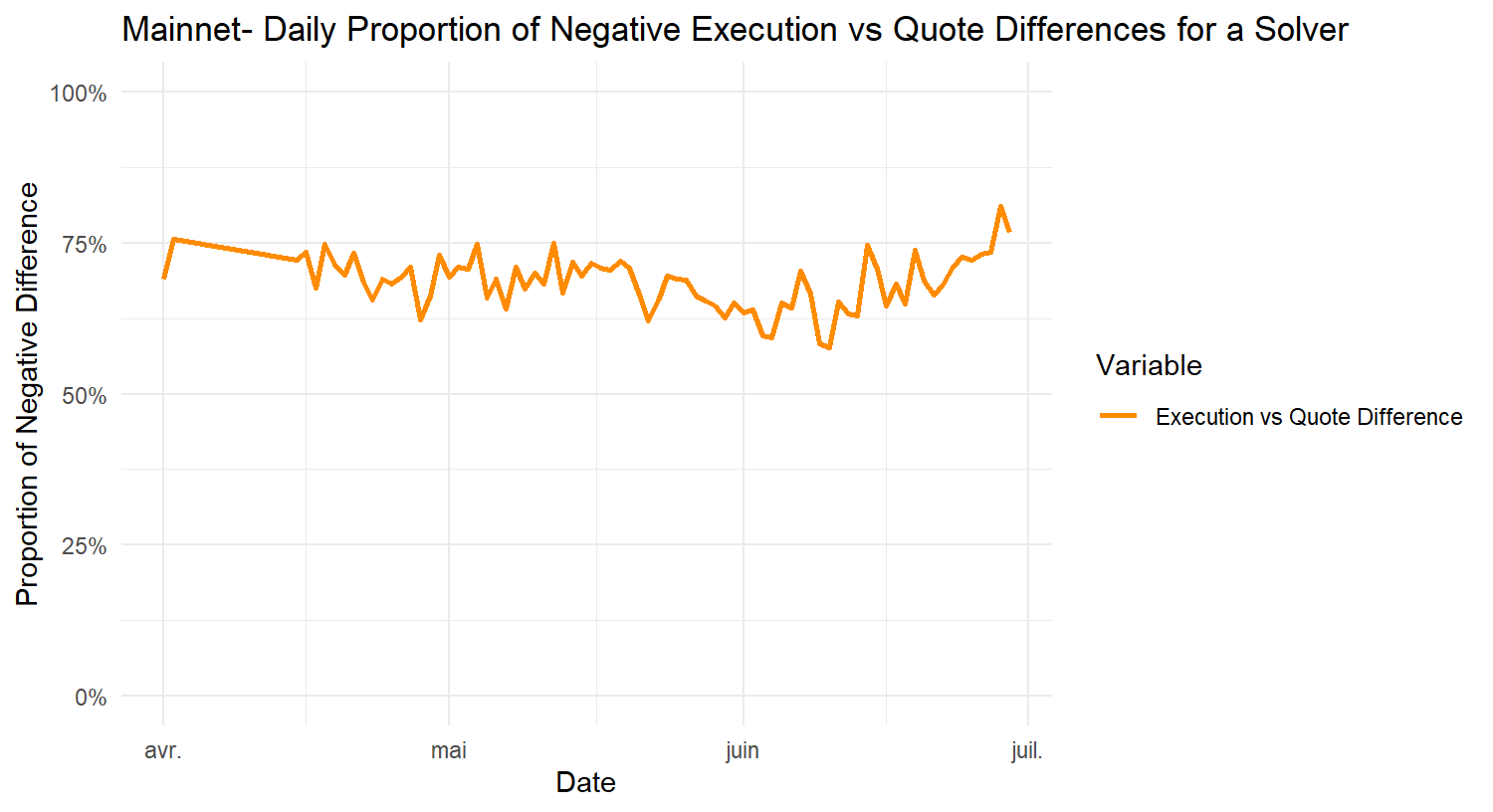
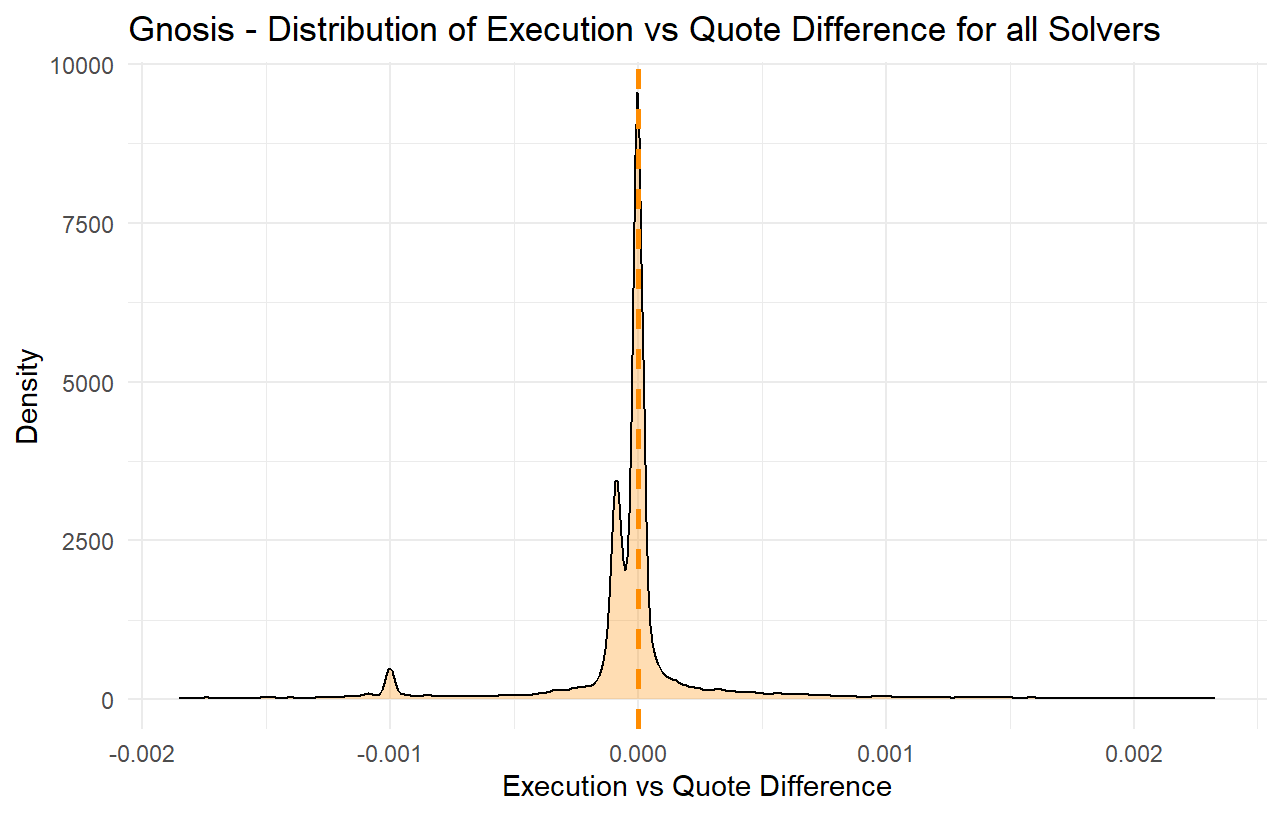
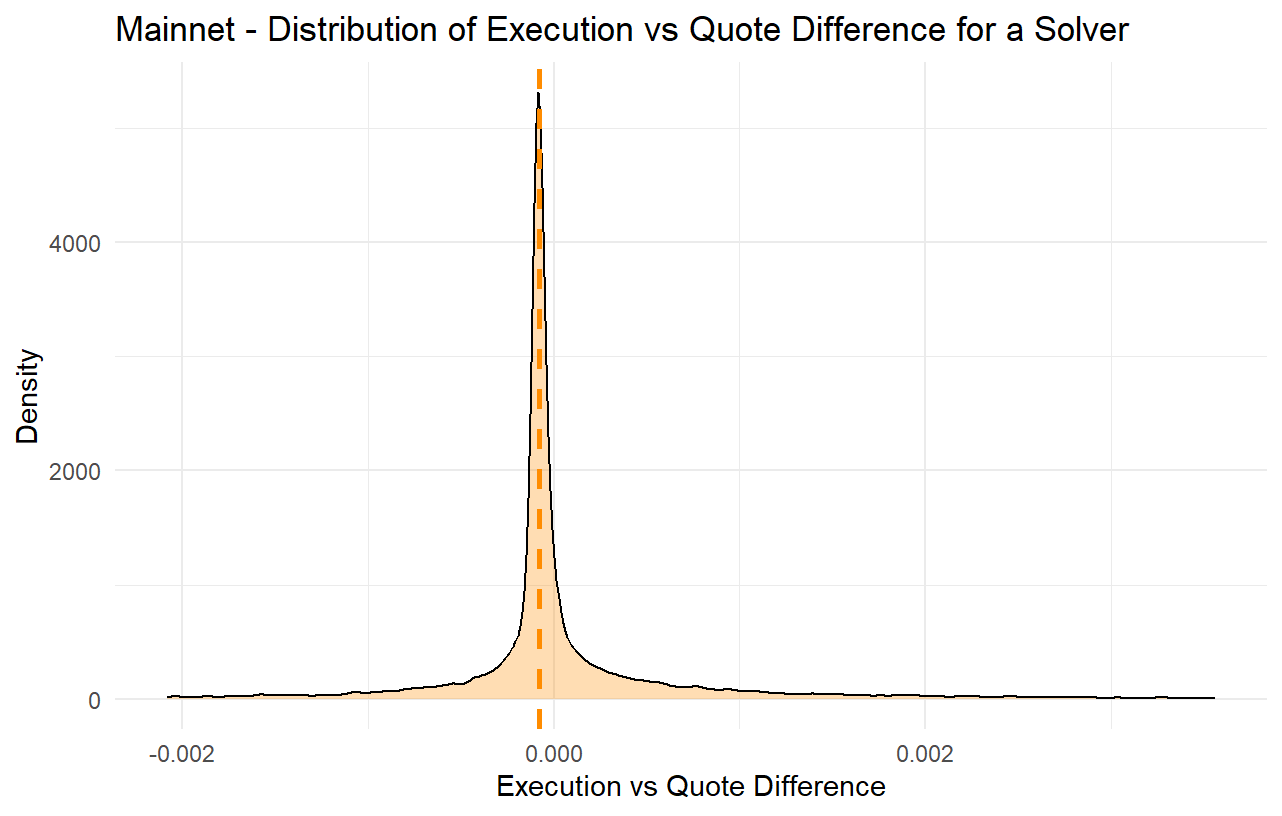
For the past several months, it has been observed that many solvers often provide overly optimistic quotes in the price estimation competition (i.e., when an order is created) while they do not provide matching bids when proposing to execute the order. Although this is often mitigated by the fact that the solver competition is very strong, in many cases it still has multiple consequences; orders sometimes get executed at worse-than-quoted prices, or get a delayed execution or no execution at all, and in many cases quoting solvers do not even attempt to execute such orders, thus passing the risk of execution to other solvers while they still claim the quoting reward, as specified by the current rewards mechanism.
In addition, an influx of trading bots on chains such as Base, combined with optimistic quotes from solvers, has resulted in a significant spike in quote rewards, and a large portion of quote rewards are now allocated to order-flow that consists of repetitive trading back and forth between two or more tokens.
For these reasons, we propose to change the incentives mechanism for the price estimation competition by adding one more condition for a quote to be eligible for a reward; that there is at least one auction where the quoting solver proposed a solution for that order that is at least as good as the quote it provided, and that solution did not get filtered out by the fairness filtering of the fair combinatorial auction mechanism.
Motivation
The incentives for the price estimation competition, first introduced in CIP-27, have proved to be instrumental in getting solvers to provide quotes for the CoW Swap UI, as well as the api and all other integrations of the protocol, creating a very strong quote competition that has made CoW Protocol very competitive in its quoting.
However, given the rather simple nature of the current rewards mechanism with a fixed reward per quote, it has been observed that quoters are now more aggressively overbidding, meaning they report quotes that they often do not intend to match when executing the order. This can lead to orders not getting executed, orders getting executed more slowly, or orders getting executed fast but at a price that is worse than the quoted price (taking advantage of the order’s slippage tolerance). In other words, the quoting mechanism is gradually getting disconnected from the actual trade executions.
Moreover, a recent phenomenon has emerged, where multiple trading bots seem to be placing a lot of orders trading two or more tokens back and forth at very tight limit prices. Many such orders, due to the overbidding in quoting, are being flagged as market orders and thus end up being eligible for quote rewards whenever they get executed. While on mainnet this has not posed much of a problem yet, on L2s, such as Base, where the gas cost is significantly lower, it has been observed that there are multiple trading bots deployed with the sole purpose of trading back and forth two (or more) assets. Although this creates additional volume to the protocol, this type of volume is rather toxic, at least when it comes to quote rewards; such orders barely contribute anything to the protocol, while they allow certain solvers that engage in ovebidding in their quoting to claim more quote rewards.
For all these reasons, we believe that the incentives mechanism needs a redesign, with the main goal to make quoting and solving again much more interdependent than it has turned out to be. Concretely we propose to continue rewarding only quotes that lead to order creation and execution, but moreover, we impose additional constraints on the quotes that are rewarded. Specifically, if a solver provided a quote for an order that was created, then we propose that the quote is rewarded only if all of the following conditions are satisfied:
- The order is a fill-or-kill market order;
- The quote is verified (i.e., its calldata successfully simulated in the autopilot);
- The order was executed (not necessarily by the quoting solver);
- The solver that provided the quote during order creation proposed an execution of the order (in at least one auction) that is at least as good as the quote, and that execution was not filtered out by the fairness filtering of the fair combinatorial auction mechanism.
We believe that the above conditions will push quoting solvers to align their quoting and solving behavior, thus making the quotes provided much more accurate and close to what the solver intends to execute onchain. Specifically, the above ensures that overbidding in quoting will not benefit a quoting solver, unless that solver is also willing to match that inflated quote during solving as well.
Specification
We propose to implement the above mechanism on all chains, starting with the accounting week of July 8 - July 15, 2025.